As I’ve been posting, I’m cataloging and posting my past presentations, and this is the last one! This talk from SIRAcon 2023 summarizes my experiences leading Site Reliability Engineering (SRE), “Measuring and Communicating Availability Risk”.
The particular focus of my SRE work was on measuring availability and availability risk, and I learned quite a bit over the 3 years or so I did SRE. One of the key lessons was that the value of measuring availability using Service Level Objectives (SLOs) was for decision support (SIRA helped with this framing). That is, SLOs and the associated measurements help make decisions about what to do, either during an incident, tactically over the course of a month, and strategically over the course of several months and into the future.
Our biggest success was the result of measuring availability in ways that supported all three timescales, using a explicitly defined customer-focused measure of “available”, we were able to construct visualizations that helped during incidents (real-time), during maintenance planning (one month), and for longer-term work (many months).
A key element of this success was the business imperative: the work supported a large and important client, who had just negotiated a significant increase in availability by no longer allowing us to count scheduled downtime against our availability target. The Service Level Indictor (SLI) we created helped our incident responders understand outages better, and the SLO we created allowed our teams to schedule maintenance with confidence or confidently defer it. A hidden benefit was that the metrics, being based on direct observations from our monitoring tools, brought together and aligned the different stakeholders on a common view of how available our systems were - the new approach we developed was even adopted by our client as an improvement.
A copy of my slides are here, and the visual notes from the talk are below! As a bonus, you’ll get to see a photo of my dog, Gertie, which was added at the last minute as part of an ongoing cats vs dogs competition at the conference.
The last “security” talk I’m cataloging this week is one that Sean Scott and I gave in some form a few times, based on Sean’s work to measure the effectiveness of our Application Security Team.
From the abstract:
How do you measure the effectiveness of security? How can you prove that security is a good investment?
In 2016, we established a security function within software engineering at Express Scripts. Taking a software engineering approach to security, we created testing services, hired developers to build tools and conduct secure code reviews, and established the AppSec Defenders training program.
In 2020, we challenged ourselves to evaluate the effectiveness of our application security program by analyzing the impact of our team’s services on pen-test findings. A 3-month data analysis found that development teams working with us fixed their pen-test findings faster and had significantly fewer new pen-test findings than teams we didn’t work with. We continued the analysis with a randomized controlled trial: by assigning new teams to work with us (or not), we have created an experiment to test the impact of our program.
We will share the specific application security practices that we believe led to these improved outcomes, how we adjusted our services in response to our findings, a recently published industry report that supports our conclusions, and the current status of our randomized controlled trial, which we expect to complete in the first half of 2021.
Results
This was an ambitious project, and we worked hard to create a rigorous study, grounded in evidence. There were a few key findings:
There was a significant improvement in the performance of the development teams we worked with, which we expected. The magnitude of the impact was large enough that we estimated we more than paid for our entire team with just the reduction in time spent fixing bugs after the fact, without considering the reduction in security risk.
Surprisingly, the level of engagement with our team had much less impact than whether or not a development team was working with us. We used this insight to scale back the amount of time we spent working with individual teams in order to work with a greater number of teams, to increase our overall impact.
Our strategies: using DAST + SAST, frequent scanning, and integrating SAST with our CI/CD pipeline for a steady scan cadence, were found to be the top 4 factors in improving remediation times by the Cyentia/Veracode State of Software Security Volume 11 report. This was quite validating for us, as we had taken this approach before the data was available.
Presentations
We presented the talk on four different occasions, all virtual due to the pandemic:
In August 2020, I gave a brief presentation based on our work at the SIRAcon Day 2 lightning round (Slides).
Later in 2020, we gave the full presentation at an internal company technical conference. One attendee suggested we present at an external security conference, so we did!
In May 2021, we presented together at Secure360. Slides from that event are here.
Finally, in October 2021, we presented again at the ISC2 Security Congress, with a few new slides, copy here. A full recording of the talk is also available on the ISC2 Events Site! (free registration required)
Note: the SIRAcon video is only available to SIRA members.
A Footnote
Finally, a footnote: this work was inspired in part by an earlier study we performed, where we measured the impact of static code analysis scanning on security bugs in software. What we found was that simply giving teams the tool or SAST reports didn’t reduce the number of security bugs. Making SAST testing “high” failures break the builds (which we encouraged teams to adopt voluntarily) or pushing teams to resolve open high findings (which was less voluntary) was necessary for improvement, as we later showed.
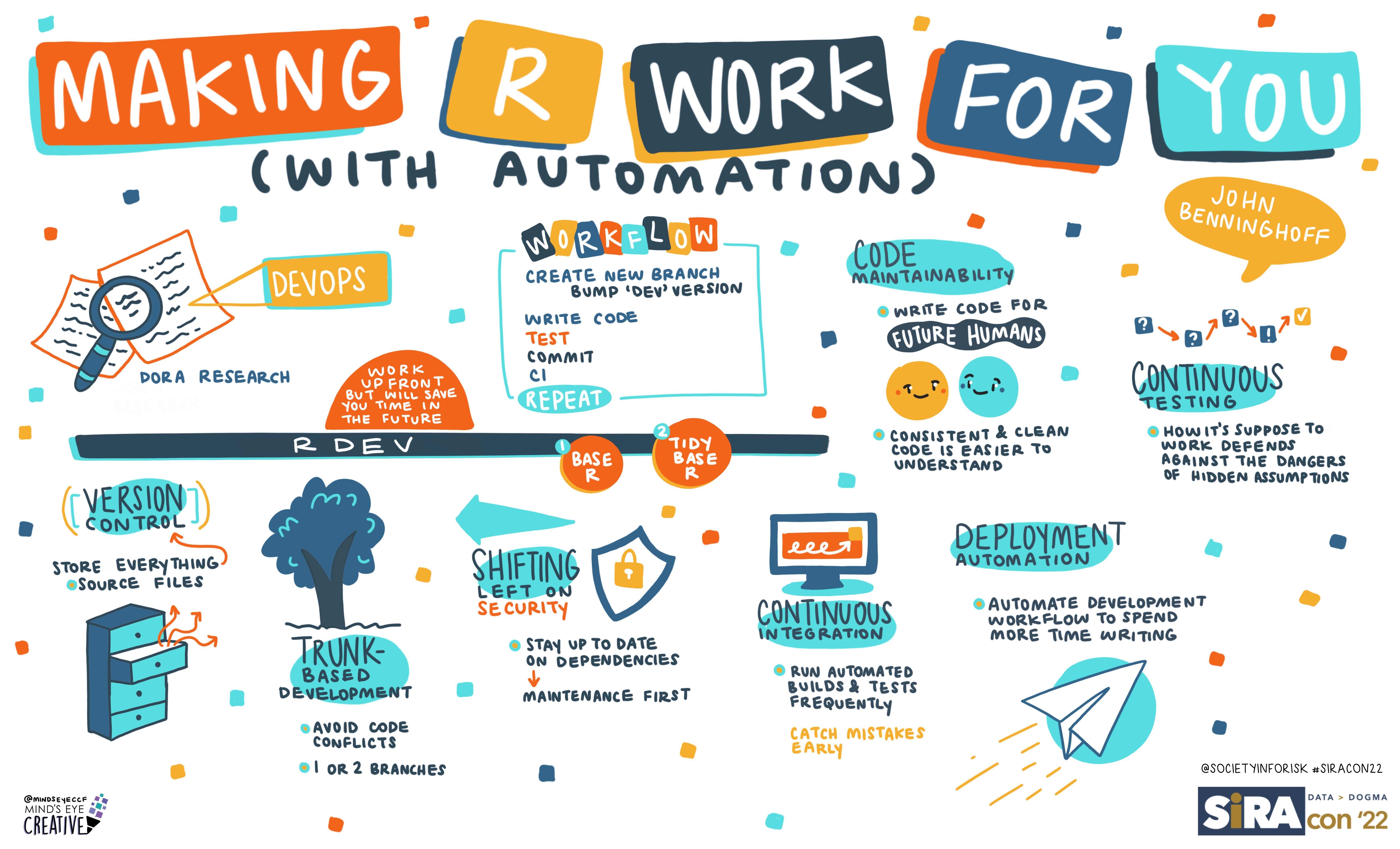
As I posted yesterday, I’m working through cataloging my past presentations, and I’m nearly done! Today I’m sharing a talk from SIRAcon 2022 that’s much different than what I typically do, “Making R Work for You (With Automation)”.
Many SIRA members do data analysis as part of their work, and talk about the results of their analysis at SIRAcon. However, we don’t often talk about the mechanics of our craft, how we go about doing data analysis. However, in 2019, Elliot Murphy gave a talk about just that, by showing how to use Jupyter (Python) and R Notebooks for data analysis. His presentation inspired me to start working with R using R Notebooks, and I wanted to share what I’d learned, and built to automate my workflow.
I think the talk went reasonably well, although it was hard to say for sure, as the conference was once again virtual that year. Unfortunately, some of the key attendees weren’t able to attend, and I didn’t get their feedback - although later one of them did watch the replay and shared that what I did was similar to his approach.
Aside from learning how to write better R code, I learned a couple of things from the experience (both doing it and talking about it):
Doing something brings deeper knowledge than reading about something. One of my goals with R was to learn good software engineering practices (documentation, testing, source code control, etc.) including DevOps practices (continuous integration and continuos delivery, CI/CD). While my experience was limited mainly to myself, I did come away with a better and deeper understanding of what it’s like to write modern software.
If writing software was more physically demanding, we’d probably do a better job creating tools and automation to help with the writing. As I noted in my talk, the carpenters who worked on our house spent a whole day setting up their environment to make it easier to move materials they were removing to the dumpster, and didn’t try to just brute-force the work. Experience and the challenge of physical labor led them to an economy of movement.
A copy of my slides are here, and the visual notes from the talk are below!